
MIT에서 2016년에 발표한 AI 가속기 Eyeriss입니다.
논문을 발표한 MIT의 Energy-Efficient Multimedia Systems (EEMS) group에서 현재까지도 Eyeriss PJT를 이어서 진행중인것 같습니다.
EEMS에서 22년도에 Energy efficient Deep learning system에 대해 이틀짜리의 교육도 진행하는데 $2500이네요.
무료 온라인이라면 꼭 듣고 싶었는데 매우 아쉽습니다.
Eyeriss Project (mit.edu) 에서 본 논문과 PJT등에 대해 자세한 내용을 볼 수 있으며 아래 내용도 논문에서 가져왔습니다.
Eyeriss Project
We will be giving a two day short course on Designing Efficient Deep Learning Systems on June 21-22, 2022 on MIT Campus. To find out more, please visit MIT Professional Education. 4/17/2020 Our book on Efficient Processing of Deep Neural Networks now avail
eyeriss.mit.edu
관심있으신분은 들어가보시길 바랍니다.
아래 리뷰는 ISSCC 16에 발표한 내용이 우선으로 Row stationary dataflow에 대해서는 MICRO에서 발표된 "USING DATAFLOW TO OPTIMIZE ENERGY EFFICIENCY OF DEEP NEURAL NETWORK ACCELERATORS"에 자세히 설명되어 있습니다.
이 부분도 아래 내용에 일부 추가하였으나 향후에 자세히 설명하겠습니다.
Abstract
Eyeriss는 Deep CNN을 위한 AI 가속기로, 이 논문에서도 DianNao처럼 off chip memory 와 on chip memory간 data movement를 최소화하기위한 방법을 중점적으로 연구하였고 RS(row stataionary) dataflow를 main idea로 제시하고 있으며 추가 개선을 위해 compression과 PE data gating도 제안함
논문 제목이 "An Energy-Efficient ReconfigurableAccelerator for Deep ConvolutionalNeural Networks" 모든걸 함축한 잘표현된 문구 같음
그리고 가장 범용적인 CNN인 AlexNet과 VGG-16을 사용하여 개선 수준 확인함
주목할점은 기존 DianNao의 경우 layout까지 진행한 simulation 결과를 바탕으로 했다면, Eyeriss는 chip out 을 통한 실제 결과를 했다는 점이 의미가 있을것 같음. 이부분은 논문의 introduction에도 잘 설명되어 있음
- Energy efficient reconfigurable accelerator for Deep CNNs
- Goals is minimizing data movement energy cost by using row stationary (RS) dataflow with 168 PE
- RS dataflow reconfigure the computation mapping of give shape (data, kernel)
- reusing data locally to reduce off chip memory access - Compression and data gating for better energy efficiency
- Alexnet@278mW(batch N=4) - 35frame/s and 0.0029 DRAM access/MAC
- VGG-16@236mW(batch N=3) - 0.7frame/s and 0.0035 DRAM access/MAC
Introduction
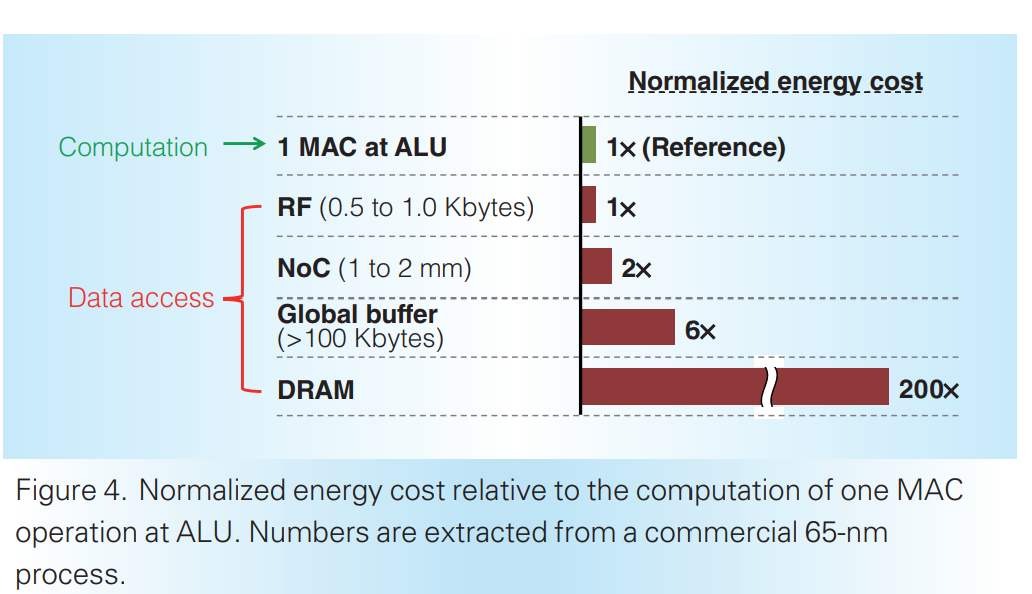
Deep CNNs은 수백메가바이트의 weight과 수십억개의 연산이 필요한만큼 main memory access가 필요해짐. Main memory access는 computation보다 energy consumption이 큼. 따라서 energy efficiency를 위해선 off chip과 on chip memory간 data movement 최소화가 필요함. 아래 메모리별 energy cost를 보면 쉽게 이해할 수 있으며 GLB까지가 internal communication임
결국 data movement를 줄이기 위해선 compute scheme 즉 dataflow 최적화가 필요하며 이를 위해 아래 4가지를 제시함
- Large amount of data (parameters, operation) creating data movement from onchip to offchip
- Need to optimize for varying shapes of high dimensional convolution with high paralleism for high throughput and reducing data movement for high energy efficiency
- Dataflow is crucial
- Data reuse : reducing data movement from on chip to off chip
- Reconfigurable HW : support different shape
- Data statistics : more energy efficiency
- compression and data adaptive processing : memory bandwidth and processing power to skip zeros
SYSTEM ARCHITECTURE
크게 core clock block (internal)과 link clock(Acc to Off-chip) block으로 나눌 수 있음.
core clock의 168개의 PE(processing element)는 같은 clock을 쓰지만 독립적으로 동작하며 kB의 spad를 포함하고 있음
Off chip memory, GLB, NoC (for inter PE communication), PE spad 의 4단계 memory hierarchy 기반의 RS dataflow를 통해 에너지 효율 개선을 확인하였고 RLC와 PE data gating을 사용하여 추가로 에너지 효율 개선함
2레벨의 control hierarchy를 가지며 각 layer 별 CNN processing을 거침.
상세 내용은 아래 참고

- 12 x 14 , 168 processing elements(PEs)
- 4 level memory hierarchy (PE scratch pad, inter PE communication, Global buffer, DRAM)
- RS (row stationary) reconfigures mapping with best energy efficiency
- NoC (network on chip) support RS dataflow (multicast and point to point single cycle data delivery)
- RLC (Run length compression) and PE data gating exploit the statistics of zero data
- Two level of control hierarchy
① Top level : Traffic between DRAM and GLB via asynchronous I/F → Traffic between GLB and PE array via NoC → operation of the RLC CODEC and ReLU
② Low level : each PE runs indepentently , not as a systolic array - Processing of a CNN layer by layer
① load the configuration bits into a 1794 b scan schain serially
② reconfigure input bits for processing of filters and fmaps
③ NoC data delivery patterns
⑤ Those are generated off line and are statically accessed at runtime
⑥ Accelerator loads tiles of the ifmaps and filter from DRAM for processing
⑦ Accelerator computes ofmaps are written back to DRAM
총 3편으로 나눠서 리뷰할 예정 다음장에는 main idea에 대해 설명하겠습니다.