
DianNao 논문 이어서 리뷰합니다. 65nm layout 설계 검증한 AI HW에 대한 내용입니다.
4. Accelerator for Small Neural Networks
large scale accelerator 를 제작하기전 small scale accelerator 를 제작하고 테스트함
neural network 구성대로 단순히 뉴런은 로직 회로로 시냅스는 ram을 사용함. 당시에 perceptron, SNN등에 많이 사용되던 방법임
결론적으로 뉴런 개수가 증가할수록 area, energy, delay 모두 증가하나 scalable하게 증가되지는 않음
결국, large scale accelerator에선 이 방법은 현실적이지 않으며 small scale에서는 시냅스를 on chip memory에 넣을 수 있었으나 large scale에서는 불가능하므로 large scale accelerator를 제작할땐 computational 과 memory hierarchy를 잘 고려해야함
- “naïve” and “greedy" approach for implementing a hard neural network accelerator
- neurons and synapses are laid out in HW , memory is only for input row and storing results
- neurons : logic circuit / synapses : latches or RAMs

※ The test results show the area, energy and delay grow quardratically with the number of neurons
- Not realistic for large scale neural network
- large scale neural network accelerator design has become the interplay between the computational and the memory hierarchy

5. Accelerator for Large Neural Networks
크게는 NFU, buffer, CP로 구성되며 작게는 buffer를 NBin, NBout, SB로 나눠 다섯개로 구성됨.
NFU는 multiplication, addtion, activation영역이 분리되어 있으며 32bit floating point연산과 16bit fixed point연산간 inferencing 결과에 차이가 없으므로 size, efficiency를 고려하여 16bit fixed point를 사용
HW적으로 동작하는 cache대신 programable한 scratch pad를 사용함. scratch pad는 2 input DMA, 1 output DMA로 구성되어 있으며 Tiling data들이 각 영역에 fit하게 들어가며 CP에서 DMA를 통해 이를 컨트롤 함
세부 동작은 아래 내용 참조.

※ Computations : Neural Functional Unit (NFU)
- Staggered pipeline : 3rd pipe line should be active after all addition performed
- No difference between 32bit floating point and 16bit fixed point
-> considering area and power, 16bit will be used for inferencing


※ Storage: NBin, NBout, SB and NFU-2 Registers
- scratchpads (on chip SRAM) for accelerator
- Cache is excellent but not optimal
- Efficient storage and easy exploitation of locality because only a few algorithms have to be manually adapted - Split buffer into three (Nbin, NBout, SB)
- width : best time and energy for each read request
ex) NB : Tn * 2Byte , SB : Tn * Tn * 2Byte
- Avoid conflict : associativity cache would be a costly energy solution - DMA
- two load DMAs (reuse and preload buffer), one store DMA
- If enough buffer capacity , DMA can preloaded to improve latency - NBin as a circular buffer
- input data are reused by changing a register index , software implementation - Local transpose in NBin for pooling layers
- Dedicated register for partial sum in NFU-2
- data transfer are a majory energy expense - Circular buffer
- NBout can be loaded into the dedicated register of NFU-2 and those register can be stored in NBout
- when NBout is idle, it can used as temporary storage buffer for partial sum of Tn
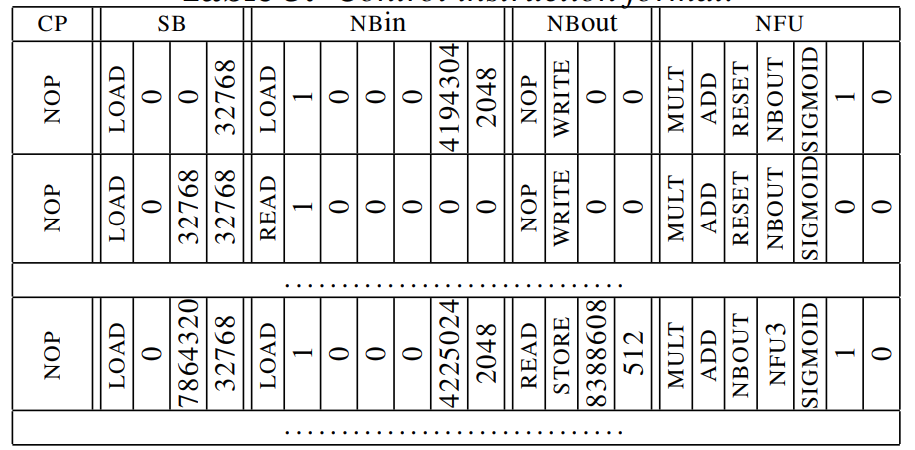
※ Control and Code
- Drive execution of DMAs both 3 buffers and NFU
- very few of the traditional features of processor like a FSM

- Every instruction has five slot, coressponding to CP
6. Experimental Methodology
C++기반 accelerator simulator, Sysnopsys tool을 사용해 layout을 진행하였고 SIMD를 비교 대상으로 삼음.
SIMD baseline 추출을 위해 기존 논문에서 사용한 McPAT modeling framework을 사용함
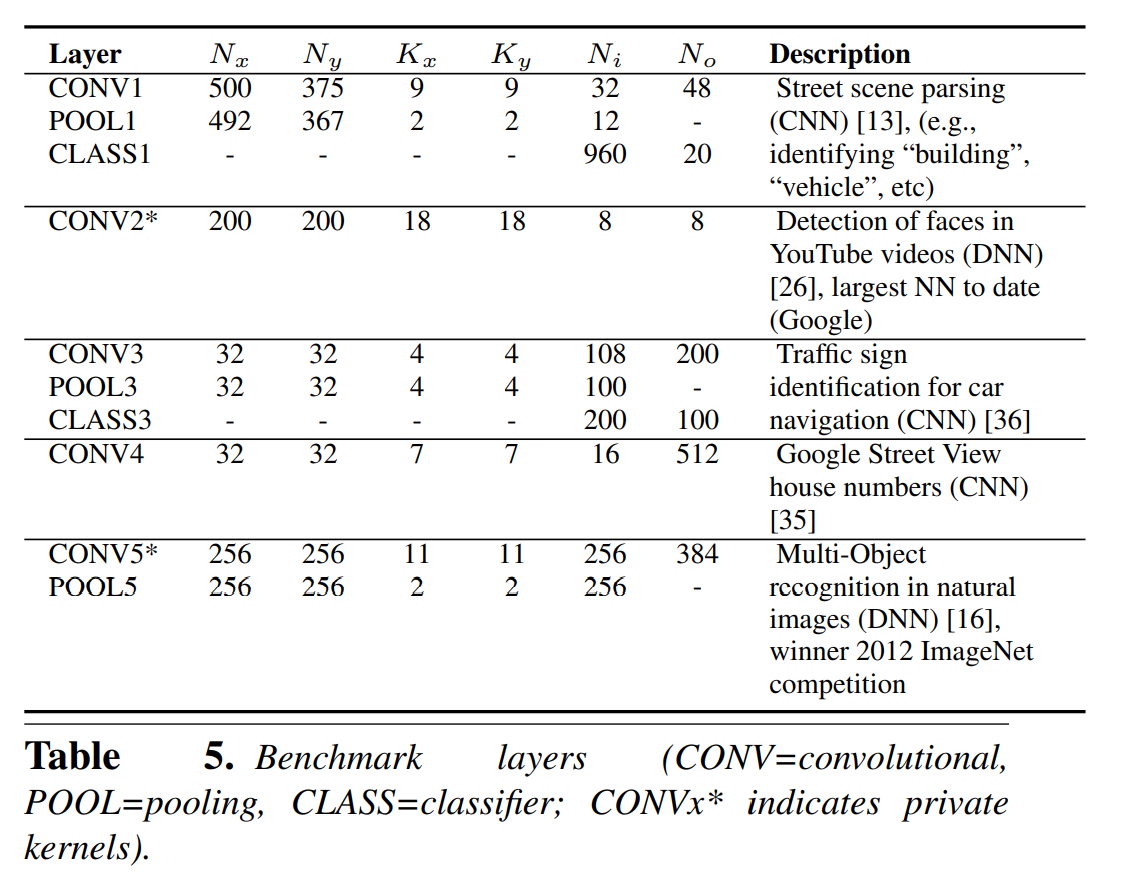
benchmark를 위해 large scale CNN에서 layer 10개를 선택하여 사용하였으면 상세 내용은 아래 테이블5 참조
- C++ Accelerator simulator : custom a cycle accurate and measuring time in number of cycle
- CAD tools (for area, energy and critical path delay)
- Synopsys ICC : placed and routing
- Synopsys VCS : simulate design
- Prime Time PX : power
- SIMD : for SIMD baseline using GEM5+McPAT combination
4-issue superscalar x86 core ith 128bit(8x16bit) SIMD unit (SSE/SSE2) @ 2GHz
L1:32KB / L2:2MB
simulator by McPAT (17.6nJ foVr 256bit read memory access)
7. Experimental Results
※ Accelerator Characteristics after Layout
synopsys를 사용하여 아래와 같이 65nm로 layout 하였으며 실제 chip out은 하지 않은듯
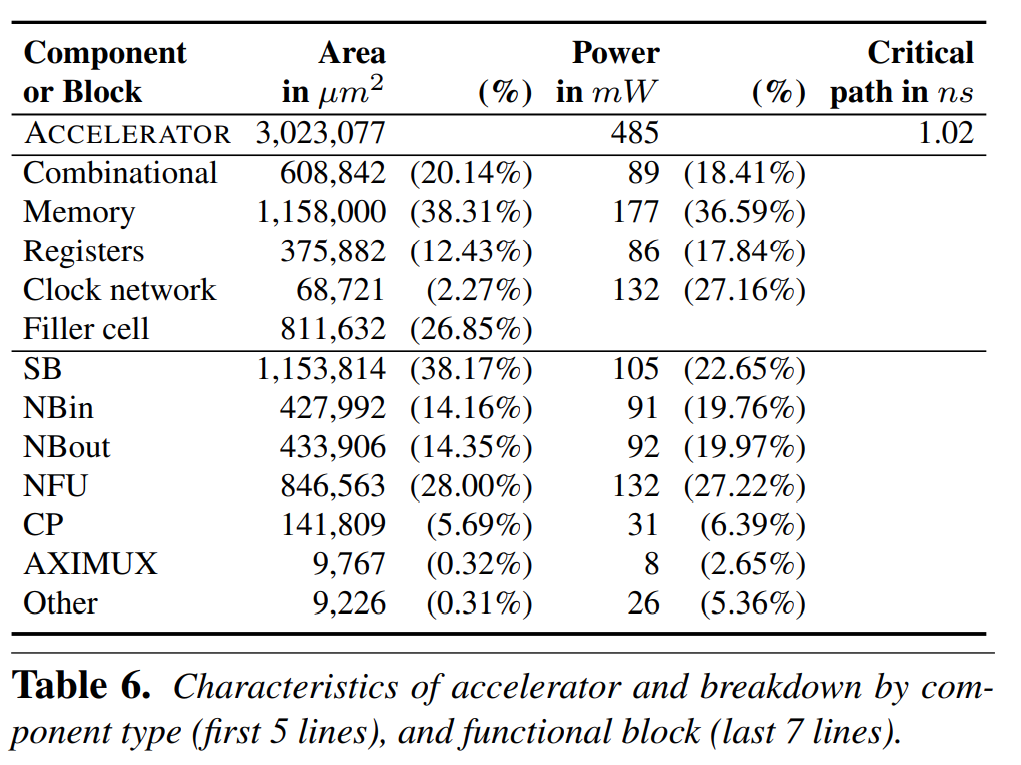
Tn=16 기준시, Table6에서 function 별 size와 power를 breakdown하여 보여주고 있으며, 이슈인 critical path 1.02ns는 NBin/NBout으로부터 data를 read할때 latency이며 다음 버전에서 critical path를 줄이는 방안을 검토할 예정임
총 RAM용량은 44KB (NBin+NBout+SB+CP instruction)이며, area와 power는 buffer (NBin/NBout/SB)에 의해 주요하게 결정 됨
Tn=8로 했을때는 total area가 0.85mm2으로 Tn=16일때보다 SB buffer가 감소되므로 3.59배 작음, 향후에 Tn=32, 64도 해볼 예정이라함. Tn=8일때 power와 성능 결과는 없음
- Synthesis and layout with Tn=16 and 64 entry buffer at 65nm using synopsys
- 452GOP/s @ 0.98GHz
- critical path is reading data out of NBin/NBout
- Refer to specific improvement at table 6
※ Time and Throughput
Figure16에서 SIMD보다 개선된 speedup을 볼 수 있음.
주요 요인 첫번째는 NBin, SB buffer에서의 preloading과 reuse의 조합으로 latency를 개선한 것임.
SIMD에는 prefetch를 반영하지 않았으며 이를통해 가장큰 성능 향상을 보인 CLASS1, CLAS3, CLASS5는 largest feature map을 가지고 있으며 locality와 preloading에 큰 영향을 받았다고보여짐. SIMD에서 prefech를 적용하면 boost효과는 상쇄될것으로 보임
CONV2는 private kernel 영향으로 POOLING은 NFU-2만 사용하므로 개선 정도가 적음.
Input feature map 개수가 적은 (Ni=12) POOL1도 상대적으로 개선 정도가 적음. 이부분의 최적화는 미래 해야할 연구임
두번째는 control and scheduling overhead임. lost cycle 최소화에 중점을 두었고 pipeline stall을 없애기 위해 NBout rotation 과 같은 기능들을 사용하였음. 이러한 optimization design이 성능 개선에 영향을줌
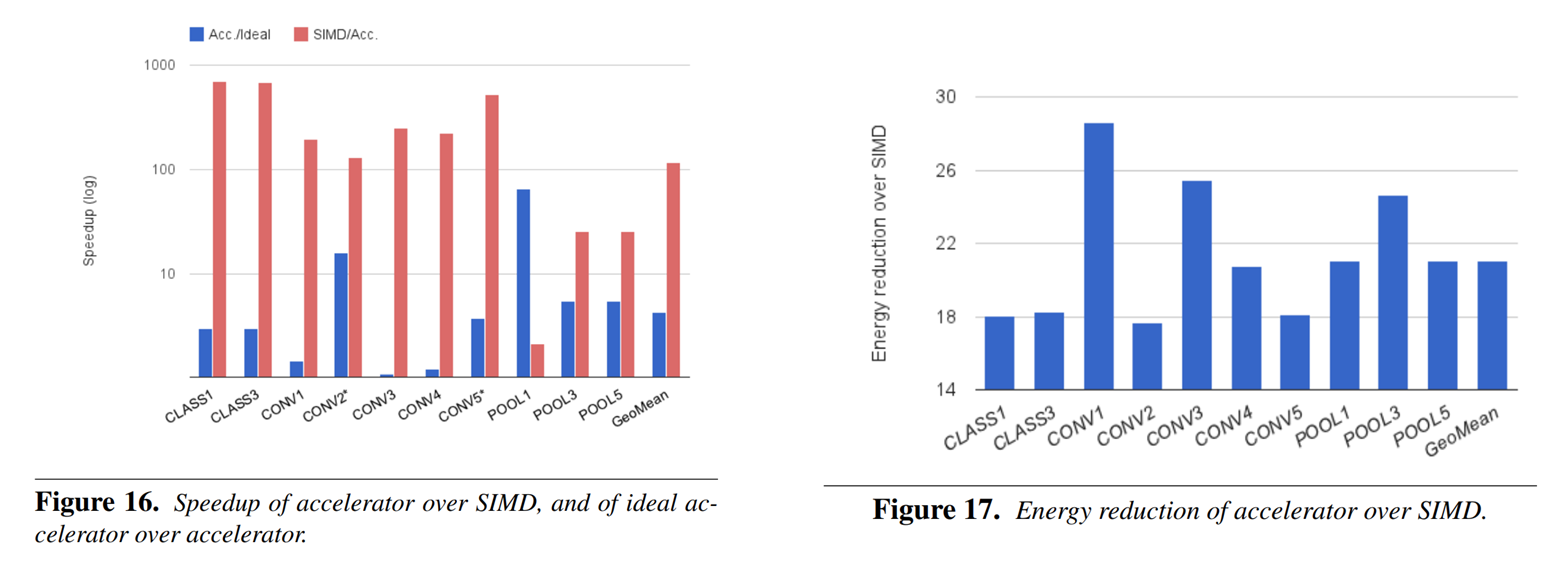
- Speed up over SIMD
① better latency tolerance due to an appropriate combination of preloading and reuse in NBin and SB buffer
② control and scheduling overhead - minimize lost cycle using NBout rotation
※ Energy
에너지 측면에서도 21.08배 SIMD보다 좋은 결과를 얻음. 하지만 이전 논문들에 비해 비율이 작은 이유는 이전 논문들은 main memory access에 의한 에너지 소모를 고려하지 않았기 때문임.
computational operator를 이용한 효율 개선도 중요하지만 결국 main memory access 개선이 없으면 암달의 법칙에 의해 효율 개선의 한계를 만나게됨
에너지 breakdown을 통해 main memory 가 주요한 인자라는걸 확인하였음. 다만 SIMD 의 경우 computation이 2/3 정도로 높아 이부분에 대한 접근도 필요하지만 향후 accelerator관점에서는 memory access 에너지 효율 개선에 중점을 둠
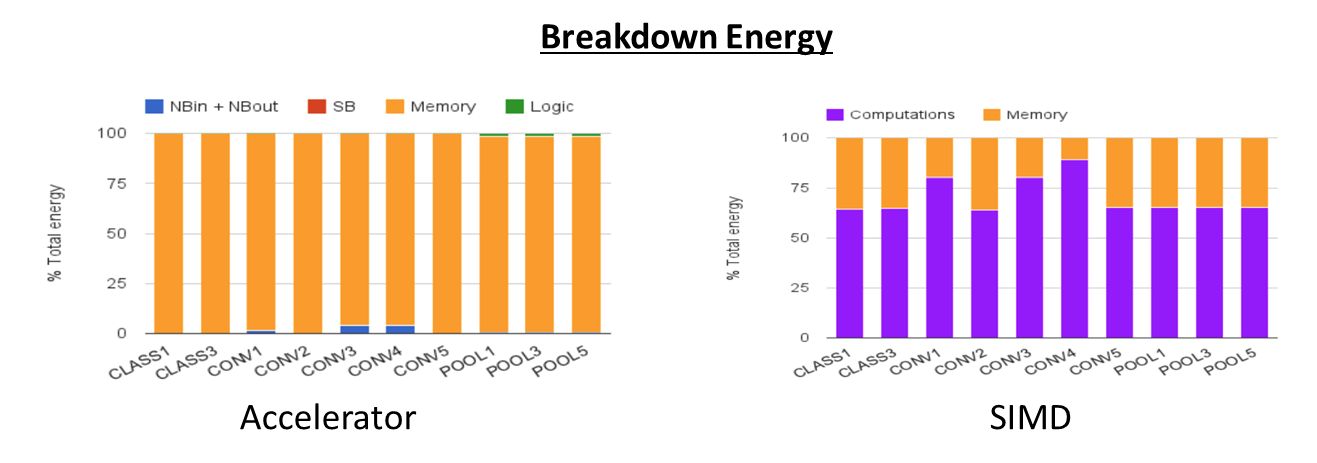
- 21.08x energy efficiency (Accelerator/SIMD)
- previous studies didn't consider energy spent in memory access
-> focus on efficient computational operator (ex : 16bit fixed point in this paper) - Amdahl's law effect for energy
-> need to bring down the energy cost of main memory access - Main memory access is obiously dominant @accelerator breakdown energy figure
- In case of SIMD, two thirds of the energy spent in computations, and only one third in memory accesses
- For future works for the accelerator should focus on reducing main memory access
Conclusions
Large scale neural netwrok 트렌드에 맞춘 맞춤형 스토리지 구조와 인접 layer 특성을 활용한 가속기를 제안하고 작은 면적의 높은 성능을 가진 가속기의 feasibility 확인함
65nm layout 설계 시뮬레이션을 통해 SIMD대비 117.87배 빠르고 21.07배 향상 된 효율의 가속기를 제안하였으며 향후 과제를 확장 시킬 예정
- In the trend of large scale neural network such as CNNs, DNNs, introducing storage structures custom designed of exploiting the locality properities of large scale layer
- Prove a feasibility of high performance machine learning accelerator in very small area
- Result
- speed up of 117.87x , energy reduction of 21.08x over 128bit 2GHz SIMD core with a normal cache hierarchy
- 65nm layout - Plan
- Planned tape out
- improving the accelerator behavior for short layer
- NFU change for Local Response Normalizaion
- further study for reducing main memory transfer cost and scalability (increasing Tn)